
Let's see a more technical feature scaling method, that we can use for scaling our dataset. It is popularly known as "Scaling to Unit Length", as all the features are scaled down using a common value. Unlike previous methods that we have studied so far, used to scale the features based on some value specific to the variable, here all the variables are used to scale the features.
Here, the scaling is done row-wise to make the complete vector has a length of 1, i.e. normalisation procedure normalises the feature vector and not the observation vector.
Note:- Scikit-learn recommends this scaling procedure for text classification or clustering.
Formula Used:-
Scaling to Unit Length can be done using 2 different ways:-
1. Using L1 Norm:-
L1 Norm or popularly known as Manhattan Distance can be used to scale the datasets.
 |
| Scaling to Unit Length using Manhattan Distance |
where l1(x) can be calculated using the below formula.
 |
| Manhattan Distance Formula |
2. Using L2 Norm:-
L2 Norm or popularly known as Euclidean Distance can be used to scale the datasets.
 |
| Scaling to Unit Length using Euclidean Distance |
where l2(x) can be calculated using the below equation
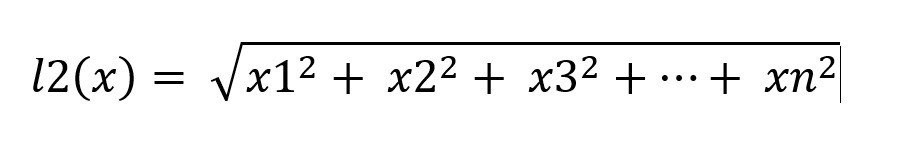 |
| Euclidean Distance Formula |
How to calculate:-
Let's see a short example of how to mathematically calculate the l1 & l2 and scale the values to unit length.
Eg:- Suppose our dataset is of a single row, i.e. just 1 observation, having 4 variables of a car.
- Length (4000)
- Width (1700)
- Mileage (20)
- Top Speed (180)
Hence, the vector will be as follow [4000,1700,20,180]
Calculating l1,
l1 = |4000| + |1700| + |20| + |180| = 5900
x(new_l1) = [4000/5900 , 1700/5900 , 20/5900 , 180/5900] = 0.678, 0.288, 0.004, 0.031
Calculating l2,
l2 = sqrt(4000^2 + 1700^2 + 20^2 + 180^2) = 4350.034
x(new_l2) = [4000/4350.034 , 1700/4350.034 , 20/4350.034 , 180/4350.034] = 0.919, 0.390, 0.005, 0.0414
Thus, the final scaled values can be given as:-
x(l1) = [0.678, 0.288, 0.004, 0.031]
x(l2) = [0.919, 0.390, 0.005, 0.0414]
Practical:-
1. Importing the necessities:-
 |
| Importing libraries for Unit length scaling |
2. Getting Data Insights
For getting any meaningful insights from the data we first need to be familiar with the data. i.e No. of Rows/Columns, Type of data, What that variable represents, their magnitude etc. etc.
To get a rough idea of our data we use the .head() method.
 |
| Boston Data Overview |
To know in detail about the dataset, i.e what each variable represents we can use .DESCR() method.
 |
| Description of Boston House Data |
To further get the mathematical details from the data, we can use the .describe() method.
 |
| Mathematical Description of Boston House Data |
3. Scaling the Data
We will be using the Normalizer method from skLearn for our data.
Using l1 norm:-
 |
| Implementing Scaling using l1 norm |
Using l2 norm:-
 |
| Implementing Scaling using l2 norm |
4. Verifying the Scaling
To verify the end result first, we need to convert the scaled_data to a pandas dataframe.
 |
| Converting scaled data to dataframe |
Describe the data before scaling data.
 |
| Describing the original data |
Describing the l1 scaled data
 |
| Describing the l1 scaled data |
Describing the l2 scaled data
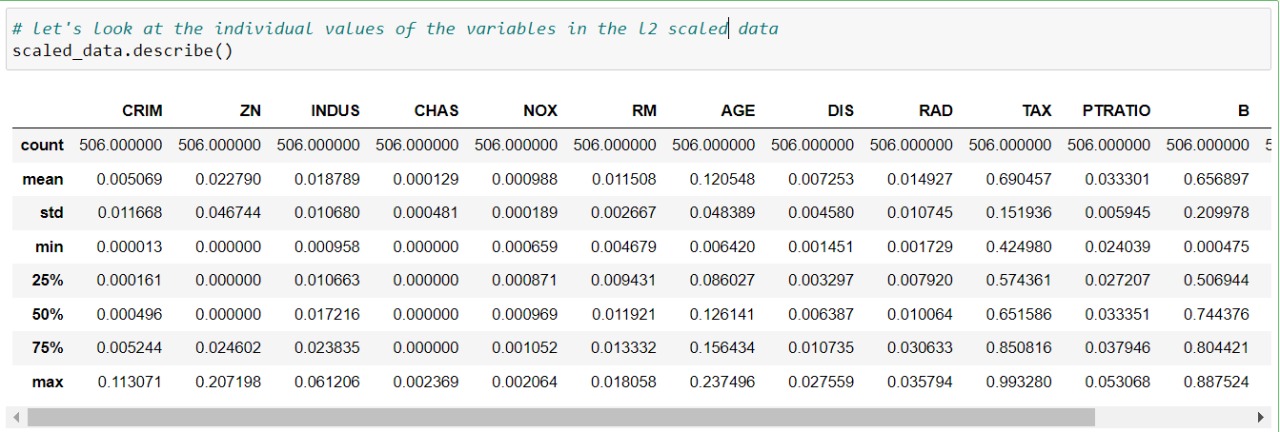 |
| Describing the l2 scaled data |
Summary
We studied Scaling vector to Unit Length, scaling the components of a feature vector such that the complete vector has a length of 1 or, in other words, a norm of 1.
Happy Learning... !!
Comments
Post a Comment