Hope you are following us and have installed Python and Anaconda in your systems, if not please refer here and install it before proceeding further.
If you have some system restrictions, then you can log in to Google Colab for free and start working there. It is very similar to Jupyter notebooks, which we will be using throughout our training.
Note:- You can download all the notebooks used in this example here
Installations
The first step is to install the NLTK library and the NLTK data.
1. Install NLTK using pip command
pip install nltk
 |
installing nltk
|
Since it is already installed in my system, it's showing "requirement already satisfied".
Instead of using Jupyter Notebook we can also create a virtual env in our system and follow these steps in conda/ python prompt.
2. Download NLTK data
 |
| nltk download |
This will open a new window NLTK Downloader as shown
It basically contains all the data and other packages for nltk, so we will blindly select "all" for now and proceed further.
Great, We are now set to experiment with nltk now.
Basic Commands
For these examples, we would be importing nltk book (refer to citations for details)
 |
| nltk book import |
Here, we have basically everything from the nltk book module. This will import some texts and sentences from the NLTK book. It has two formats list of words as 'sent' and a text as 'text'.
 |
sentences and texts in nltk book
|
We can view the texts and sentences present in them directly by using sent# or text# as shown above in the image. The first basic action that we want to perform on any text is to search a tokens or N-grams in our text. To simplify our work of manually searching for a token, nltk provides us with a function known as "nltk.concordance" which will not only search the given token but will also provide the complete sentence where it has been used, as shown below:-
Here, we can see within no time it was able to read the entire text and find around 350 occurrences of the word "World".
Next, we might want to search for different tokens with a similar meaning as the tokens we searched or thinking of. This can be done easily by using the function "nltk.similar" as shown below
Here, we can see it was able to find sentences with words such as "earth" or "country union" which is similar to the original word "world".
The next thing that we might want to know about our text data is in what context a group of words have been used in our text. Let's say we found out the most similar word to our original word ("world") is the word "Earth", now we might want to know in what context are these words used for that we can use the function "nltk.common_contexts()" |
This means the words would be present as "the world and", "the earth and" and so on in the text.
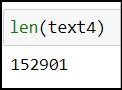
We searched our data and found similar words in it, but do we know the size of the text that we are dealing with..!! No worries it is as simple as "len()" in Python. It will return the number of tokens present in the text.
 |
| length of text |
How about knowing the distinct tokens present in the text? It is again a simple step.. using a "set()" to create a set of distinct tokens and counting its size, as shown below
 |
| length of distinct tokens |
How about knowing the occurrences of a particular word/token in the text... We can simply use a 'count()' function to count them.
 |
number of repetitions of a word
Till now we have performed basic operations on the nltk text. Now, let's try to perform some more complex indexing operations. Indexing is like knowing the position of the element we want to access or vice versa, i.e. in simple terms accessing the elements directly using the position.
 | Accessing elements based on index
This was a simple example to show how we can easily access the elements based on their positions in nltk.
So now let's try to find out the first occurrence of our token "world", for this we would be using the "index()" function
Here, we can see the first appearance of the token "world" occurred at the 921st position from the start.
Next, let's try to slice out the 5 tokens before and after the first appearance of the 'world' token.
Here we can see that 'world' was the last word in the sentence. So, by slicing the text in our desired length we can actually create sub-sentences from it. We can further experiment with slices by changing the start and end limits in the list. The basic format for slicing is
list_var[start_index : end_index]
Here, if skip the start_index then it will get all the tokens from 0 index till the end_index specified and vice versa if we skip the end_index. Try experimenting with it and comment on your findings below...
Now, let's try some more interesting things with the lists.
We can add 2 or more lists together with a simple '+' operator. This operation of adding 2 or more lists together is known as 'Concatenation'. For adding a single value to a list we can use the 'append' operator as shown below

A quick recap of string operations in python
One interesting thing before we close this introductory session on NLTK, we have seen a few quick and easy functions for getting information about the token and its distribution in the text apart from that we can also easily visualize them with a simple function "dispersion_plot()"
The above plot shows the positions of the different tokens across the entire text. We can see the token 'earth' is hardly present across the entire text, whereas the token country is densely present at the end portion of the text.
Now comes the real magic part which we all want somewhere our models to do is to generate text. So we can do it here with nltk library with a simple 'generate' which can generate some random text based on our text provided as shown below.
So, how this work is it gathers statistics about word sequences reuses common words and phrases from the source text and gives us a sense of its style and content.
Try, experimenting with all these functions and let us know how differently were you able to use it.
|
|
Git Hub Repo:-
NLP RepositoryCitations



















Comments
Post a Comment